
Overview
In this data exploration, you will:
- Become familiar with the Scikit Learn machine learning library
- Use the library to build a machine learning model.
- Use that model to make predictions.
Throughout this exploration, when you're asked to use a new function or library, we'll usually provide a link to that function's documentation, or a tutorial related to it.
Introduction
As with our previous data explorations, this assignment uses Google Colab. For more information on using Google Colab, including how to submit assignments with it, please see the information in Data Exploration 01
Assignment
You're working with a team of botanists to develop a flower classification system.
Your assignment is to build a k-Nearest Neighbors model to classify flowers based on their petal and sepal sizes.
Notes about the data
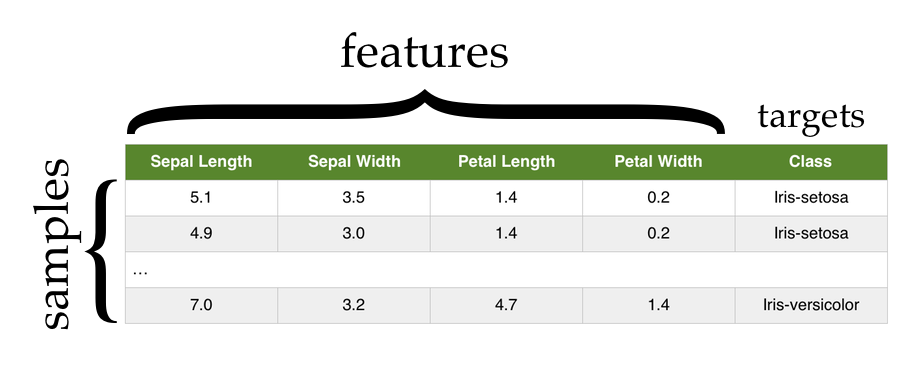
The dataset contains sepal and petal measurements for several samples of iris flowers.
Each row in the data is a sample. There are five columns.
The first four columns contain the feature values for each sample: sepal_length, sepal_width, petal_length, and petal_width.
The fifth column, species, is our target value.
Remember, the purpose of supervised learning is to build a model that can predict the target value from the feature values.
Colab Link
Click on the Open In Colab button below to open a Google Colab notebook with the template for this assignment. Once you've completed the assignment, don't forget to take the corresponding quiz in Canvas.
| Pandas | Polars |
|---|---|
Teacher's Solution
Once you have absolutely exhausted all of your best efforts in solving the data exploration problems, and you are stuck on where to go next, you can view the teacher's solution here or here for polars.